
DB ————> TABELLE (TABLE)
|
|
RIGHE (ROW)
|
|
CAMPI (FIELD)
SERVER
____________________________
| |
| ====================== |————-> DB
| |
| ====================== |————-> APACHE
| | (WEB SERVICE)
| ====================== |————-> SMTP1
| |
| ====================== |—— ——> DNS
> Il browser opera una query DNS per ottenere, ad esempio, l’indirizzo pubblico di Google. Il router organizza questo dialogo. Anche il nostro indirizzo IP privato assume la forma del provider pubblico (per esempio quello della Telecom) con cui dialogare con altri indirizzo pubblici IP.
> Esempi di indirizzi IP: 172.16.x.y <–> 172.32.x.y di solito usati dalla pubblica amministrazione, 10.x.y.z da Fastweb.
> IPv4: (Internet Protocol version 4) è la quarta revisione dell’Internet Protocol. È il più usato a livello di rete, poiché fa parte della suite di protocolli Internet.
> IPv6: è la versione dell’Internet Protocol designata come successore dell’IPv4. Tale protocollo introduce alcuni nuovi servizi e semplifica molto la configurazione e la gestione delle reti IP. La sua caratteristica più importante è il più ampio spazio di indirizzamento: IPv6 riserva 128 bit per gli indirizzi IP e gestisce 2128 (circa 3,4 × 1038) indirizzi; IPv4 riserva 32 bit per l’indirizzamento e gestisce 232 (circa 4,3 × 109) indirizzi.
> NAT: il network address translation o NAT, ovvero traduzione degli indirizzi di rete, conosciuto anche come network masquerading, native address translation, è una tecnica che consiste nel modificare gli indirizzi IP dei pacchetti in transito su un sistema che agisce da router all’interno di una comunicazione tra due o più host2. Il NAT è spesso implementato dai router e dai firewall. Si può distinguere tra source NAT (SNAT) e destination NAT (DNAT), a seconda che venga modificato l’indirizzo sorgente o l’indirizzo destinazione del pacchetto che inizia una nuova connessione. Storicamente il NAT si è affermato come mezzo per ovviare alla scarsità di indirizzi IP pubblici disponibili, soprattutto in quei paesi che, a differenza degli USA, hanno meno spazio di indirizzamento IP allocato pro-capite.
> Peer to Peer: comunicazione diretta fra utenti. Per indirizzare gli utenti ogni router è provvisto di PORT FORWARD3, per cui esso fa in modo che tutte le richieste che arrivano al router siano indirizzate a quella porta.
> La scheda ETHERNET4 necessita di 4 informazioni per comunicare: 1-l’indirizzo IP; 2- NET MASK ( 255.255.255.0 ) che serve per capire quali altri indirizzi IP sono da considerare locali o remoti. Ad esempio: 192.168.1.2 è l’IP mentre 255.255.255.0 è la NET MASK. Così la macchina capisce che tutti i numeri inclusi nell’uno dell’IP, confrontato con la NET MASK, sono locali e non deve disturbare il router; 3- GATEWAY: indirizzo privato locale in entrata. 192.168.1.1; 4- DNS5: 192.168.1.1 è il router che fa da server DNS. Traduce i nomi attraverso un programma interno. Il router è, infatti, un piccolo PC. Il DNS è un servizio autorizzativo ufficiale.
> TTL: Time to Live. Secondi di validità per cui le informazioni vengono trattenute sul router per un periodo se servono ancora, ovvero tempo di vita di un dato su un computer di una rete.
> DHCP è un servizio che serve a “ottenere automaticamente i dati”, cioè rilascia un indirizzo IP utilizzabile. Il Dynamic Host Configuration Protocol (protocollo di configurazione IP dinamica) è un protocollo di rete di livello applicativo che permette ai dispositivi o terminali di una certa rete locale di ricevere automaticamente a ogni richiesta di accesso a una rete IP (quale una LAN) la configurazione IP necessaria per stabilire una connessione e operare su una rete più ampia basata su Internet Protocol, cioè interoperare con tutte le altre sottoreti scambiandosi dati, purché anch’esse integrate allo stesso modo con il protocollo IP.
> TCP/IP: indirizzo epistatico e dinamico. Transmition Control Protocol possiede un meccanismo per il recupero degli errori. Inoltre, il TCP gestisce delle porte (65535) TCP. La cosa basilare di questo protocollo sono proprio le porte.
> IMAP: protocollo per la ricezione della posta elettronica, dialoga con la porta 143 o 993(ssl).
> Il server web Apache si mette in ascolto alla porta 80 o 443(ssl). La SMTP viaggia sulla porta 25. MySql utilizza la porta 3306.
MIO PC
________ _________
|___1___| |________|
|___2___| |________|
|_______| |________|
|_______| |________|
APACHE WEB SERVICE <—-|__443__| <——–>ROUTER<——->|__1025__| PACCHETTO
|_______| |________|
|_______| |________|
|_______| |________|
|_______| |________|
|_65535_| |________|
> le cartelle condivise in rete locale utilizzano la porta 445.
> UDP/IP: stessa cosa del TCP, ma non fa controlli di trasmissione. Perciò, se il pacchetto va perso, va perso e basta. È utilizzabile per il peer to peer o per lo streaming.
> NTP: Network Time Protocol. Invia pacchetti con l’orario (atomico). È un protocollo per sincronizzare gli orologi dei computer all’interno di una rete a commutazione di pacchetto, quindi con tempi di latenza variabili ed inaffidabili. L’NTP è un protocollo client-server appartenente al livello applicativo ed è in ascolto sulla porta UDP 123.
> L’IP 127.0.0.1 è un indirizzo universale di LOCAL HOST che serve all’autoriconoscimento di ogni computer. Può essere usato dalle applicazioni per comunicare con lo stesso sistema su cui sono in esecuzione. Essere in grado di comunicare con la propria macchina locale come se fosse una macchina remota è utile a scopo di test, nonché per contattare servizi che si trovano sulla propria macchina, ma che il client si aspetta siano remoti.
> www.easyphp.org versione 14.1 o 16.1 www.phpmyadmin.net
> L’ INNODB è un motore per il salvataggio di dati (Storage Engine) per MySQL, fornito in tutte le sue distribuzioni. La sua caratteristica principale è quella di supportare le transazioni di tipo ACID6. La licenza è la GNU GPL versione 2.
—
> Ci sono 3 versioni del MySql: Enterprise; Cluster; Community, tutte in Open Source. Ultimamente MySql è stato acquistato da Oracle che lo ha sviluppato senza farne sparire la versione gratuita.
> In database, al posto del backup si usa il termine Dump7.
> Ecco le principali istruzioni con cui operare sul nostro database.
SELECT: con l’istruzione SELECT di SQL possiamo creare degli script di interrogazione al database, detti query.
Esempio: SELECT * FROM nome_tabella, dove * sta per tutti i campi. La query SELECT id_autore FROM autori estrae tutti i campi dalla tabella autori. Al posto di * posso usare i nomi dei campi che mi interessa estrarre.
SELECT nome, cognome FROM utenti;
SELECT nome, cognome FROM utenti WHERE utente_id = 1;
DELETE: Consente di rimuovere righe da una tabella.
DELETE [ FROM ] table_name [ WHERE < search_condition > ]
FROM
- Parola chiave facoltativa che può essere utilizzata tra la parola chiave DELETE e il valore table_name di destinazione.
- table_name
- Nome della tabella da cui è necessario rimuovere le righe.
- WHERE
- Specifica le condizioni utilizzate per limitare il numero di righe eliminate.
- <search_condition>
- Specifica le condizioni restrittive relative alle righe da eliminare. Non esistono limiti al numero di predicati che possono essere inclusi in una condizione di ricerca.
INSERT: Consente di aggiungere una o più righe a una tabella o a una vista8 in MySQL.
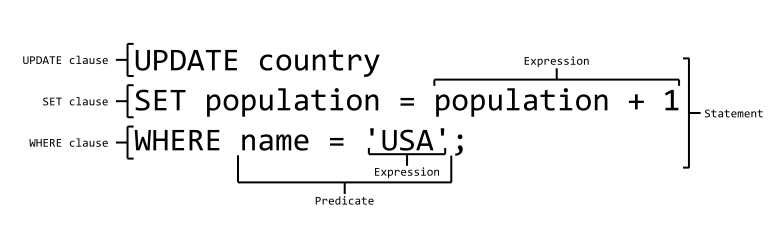
UPDATE: grazie al quale è possibile aggiornare i dati già presenti all’interno di una tabella.
UPDATE nome_tabella SET nome_campo = ‘valore‘. Per aggiornare più di una riga contemporaneamente scriverò:
UPDATE provando
SET nome = ‘gianni’
WHERE indice = 4;
UPDATE provando
SET nome = ‘giulio’
WHERE indice = 5;
ALTER: Per modifica di una struttura di una tabella si intende l’aggiunta di un campo, la modifica della nomenclatura di un campo esistente, di un tipo di dato o per stabilire che un campo sia NULL (non richiesto) o NOT NULL (obbligatorio).
La sintassi per aggiungere un campo ad una tabella è la seguente:
ALTER TABLE nome_tabella ADD nome_campo tipo_dato; cioè: ALTER TABLE utenti ADD zeta VARCHAR(20) CHARACTER SET utf8 (in questo caso me lo dà automaticamente NULL, poiché non spiegato diversamente); ALTER TABLE utenti ADD zeta VARCHAR(20) CHARACTER SET utf8 COLLATE utf8_swedish_ci NOT NULL ci restituisce un risultato con campo NOT NULL. Con: ALTER TABLE utenti DROP zeta cancelliamo il campo aggiunto prima, di nome zeta. > COLLATE: si tratta di una clausola associata a CREATE e ALTER DATABASE o TABLE. Ad ogni set di caratteri sono associate una o più collation, che rappresentano i modi possibili di confrontare le stringhe di caratteri facenti parte di quel character set.
> I charset sono le cose più vicine ai font. Sono insiemi di caratteri specifici per paesi diversi. Il tipo di caratter INT (INTEGER) mi dà 232 possibilità di memorizzazione. VARCHAR: contiene un numero variabile di caratteri. Il NULL, come valore di campo, ci permette di sapere se il campo può rimanere vuoto o meno.
> != (diverso)
> SET: Imposta la variabile locale specificata, creata in precedenza tramite l’istruzione DECLARE @local_variable, sul valore specificato.
> WHERE: Sebbene si tratti di una clausola anziché di un’istruzione ed essendo utilizzata da quasi tutte le altre istruzioni si è preferito trattarla a parte. La sua unica finalità è quella di limitare le selezioni ed includere solo le righe che corrispondono ai criteri specificati. Il suo utilizzo generale è: WHERE <campo> <predicato> <valori> .
= è uguale al valore
< è minore del valore
> è maggiore del valore
<= è minore oppure uguale al valore
>= è maggiore oppure uguale al valore
<> è differente dal valore
LIKE è similare al valore
NOT LIKE non è similare al valore
BETWEEN è compreso tra i due valori specificato a seguito
NOT BETWEEN non è compreso tra i due valori
IS NULL è il valore NULL
IS NOT NULL non è il valore NULL
Alcuni database consentono l’uso di ulteriori predicati:
!= non è uguale (cioè è differente) al valore
!< non è minore (cioè è maggiore o uguale) del valore
!> non è maggiore (cioè è minore o uguale) del valore
IN corrisponde ad uno dei valori specificati a seguito
NOT IN non corrisponde ad alcuno dei valori specificati a seguito
> AND: permette l’esistenza di condizioni multiple in una clausola WHERE: SELECT column1, column2, columnN
FROM table_name WHERE [condition1] AND [condition2]...AND [conditionN];
—
> DUMP: con l’attivazione del sistema di binlog è possibile ricostruire le tabelle prima del disastro. È un elemento di un database contenente un riepilogo della struttura delle tabelle del database medesimo e/o i relativi dati, ed è normalmente nella forma di una lista di dichiarazioni SQL. Tale dump è usato per lo più per fare il backup del database, poiché i suoi contenuti possono essere ripristinati nel caso di perdita di dati.
> Comandi OPTIMIZE e REPAIR. Il comando OPTIMIZE deframmenta i dati contenuti in una tabella, occupando gli spazi lasciati vuoti da altri dati cancellati. Il comando REPAIR TABLE può essere utilizzato per tentare di correggere degli errori presenti all’interno di tabelle MyISAM o ARCHIVE. Non è compatibile, invece, con lo storage engine InnoDB.
Se usato per le tabelle MyISAM il suo utilizzo è del tutto equivalente, sul prompt di DOS, a:
myisamchk --recover nome_tabella . Il MySql blocca la tabella e ricostruisce i file utili della tabella. Sono comandi contenuti in myisamchk. Per lavorare il server deve essere spento. > mysqldump -u root enaip utenti (backup) > mysqladmin -u root -p shutdown (per chiudere chiedendo la password) > exit o quit serve a disconnettersi dal client MySql > mysql -u root enaip2 < d:\sql\dump_enaip.sql mysql -u root enaip > d:\sql\dump_enaip.sql > mysql -u root enaip2 < d:\sql\stat.sql > session_id: sulla tabella che abbiamo scaricato, raccoglie le sessioni (cookies) di dialogo. Sono le session id dell'utente loggato. > Comando ENUM: una lista in cui ogni parola è associata ad un numero. Si usa ENUM in una tabella di status (es.: confermato, attivo, inattivo...) > Funzione YEAR: restituisce un valore intero che rappresenta la parte dell'anno di date specificata. Esempio: SELECT YEAR('2016-05-02') mi restituisce: 2016. Funzioni ed Operatori. Le funzioni restituiscono dei risultati, mentre i processi eseguono dei comandi senza dare risultati. Il simbolo = serve ad assegnare BETWEEN.....AND...... controlla se un valore è all'interno di una gamma di valori. > maggiore >= maggiore o uguale IS NOT NULL non è di valore NULL IS NULL è di valore NULL < minore <= minore o uguale LIKE come, similare <> non uguale NOT LIKE non è come, non similare (funzione) DATE DATE FORMAT formatta la data come da specifica >SELECT CURDATE(); mi restituisce la data corrente con separatoriSELECT CURDATE() + 0; mi restituisce la data corrente senza separatoriSELECT CURTIME(); mi restituisce l'ora corrente con separatoriSELECT CURTIME() + 0; mi restituisce l'ora corrente senza separatoriSELECT ADDTIME('2007-12-31 23:59:59.999999', '1 1:1:1.000002');aggiunge 1 giorno, 7 ora, 1 minuto, 1 secondo e 2 centomillesimi di secondo alla data iniziale: '2008-01-02 01:01:01.000001'>SELECT CONVERT_TZ('2004-01-01 12:00:00','+00:00','+10:00'); aggiunge 10 ore, in caso di calcolo del fuso orario, alla data e ora di partenza: '2004-01-01 22:00:00' >SELECT CONVERT_TZ('2004-01-01 12:00:00','GMT','MET'); mi dà come risultato-> '2004-01-01 13:00:00'. MET significa Moscow Europe Time e deve essere settato in maniera appropriata nella tabella di conversione tempo.> SELECT DATEDIFF('2007-12-31 23:59:59','2007-12-30');restituisce la differenza in giorni tra la data iniziale e quella finale. In questo caso sarà 1.>SELECT '2008-12-31 23:59:59' + INTERVAL 1 SECOND; mi restituisce -> '2009-01-01 00:00:00' >SELECT DATE_ADD('2010-12-31 23:59:59', INTERVAL 1 DAY);mi restituisce -> '2011-01-01 23:59:59' > SELECT DATE_ADD("2016-02-29", INTERVAL 1 YEAR) AS DATE_TEST [è per verificare e non incappare nell'errore dell'anno bisestile] > TRIM rimuove caratteri generici e spazi all'inizio (LTRIM) o alla fine del campo (RTRIM) . SELECT TRIM(reference) AS reference FROM stat > CONCAT serve, ad esempio, ad ottenere dai campi nome e cognome un campo unico. Restituisce stringhe concatenate. SELECT CONCAT(nome, ' ' , cognome) AS nome_cognome FROM utenti SELECT TRIM(CONCAT(nome, ' ', cognome)) AS nome_cognome FROM utenti > CONCAT_WS , concatenazione con separatore. Esempio: SELECT CONCAT_WS('-', nome, cognome) AS nominativo FROM provando restituisce nome e cognome separati da lineetta. > LCASE , trasforma tutto in minuscolo. Esempio: SELECT LCASE(cognome) FROM provando mi restituisce il campo cognome tutto minuscolo. > UCASE , trasforma tutto in maiuscolo. Esempio: SELECT UCASE(cognome) FROM provando mi restituisce il campo cognome tutto maiuscolo. > UCFIRST è una funzione PHP che trasforma il primo carattere in maiuscolo. In MYSQL, non essendoci questo comando, si deve scrivere quanto segue: SELECT CONCAT(UPPER(LEFT(nome, 1), > SELECT CONCAT (UPPER(SUBSTRING(nome, 1, 1) LOWER(SUBSTRING(nome FROM 2))) AS temp FROM provando mi restituisce il campo nome con le iniziali maiuscole. > LOCATE serve ad individuare una sottostringa all'interno di una stringa. Esempio: SELECT * FROM provando WHERE LOCATE('ia', nome) mi restituisce uno o più records in cui vi sia, nel campo nome, una sottostringa 'ia'. > SUBSTRING serve ad individuare una sottostringa all'interno di una stringa. Esempio: SELECT SUBSTRING('bodyart', 5); mi restituirà 'art'. SELECT SUBSTRING('bootandboot' from 4); mi restituirà 'tandboot'. SELECT SUBSTRING('superbodyart', 5, 6); mi restituirà 'rbodya'. SELECT SUBSTRING('semiramide', -3); mi restituirà 'ide'. SELECT SUBSTRING(('semiramide', -5, 3); mi restituirà 'ami'. SELECT SUBSTRING('semiramide', -4 for 2); mi restituirà 'mi'. Se voglio trovare, nel campo cognome della tabella provando composta dai seguenti cognomi: rossi, verdi, verdi, marroni, le ultime 4 lettere, visualizzandone solo 2, scriverò: SELECT cognome, SUBSTRING(cognome, -4, 2) FROM provando; mi restituirà: os, er, er, ro. >SELECT UCASE(nome) FROM provando(restituisce i contenuti del campo nome tutti in maiuscolo) > UPDATE utenti SET nome2 = "Mario" WHERE utente_id = 1 restituisce il campo nome2 all'indice 1 come Mario. > UPDATE utenti SET nome2 = UPPER(SUBSTRING(nome,1,1)) restituisce l'iniziale maiuscola del campo nome in nome2, senza altre lettere. > Se digito: INSERT INTO provando(nome2) SELECT nome FROM provando avrò, come risultato, la copia dei contenuti dei campi in altri 4 nuovi record (aggiuntivi). > Se digito: DELETE FROM provando WHERE indice = 12 avrò come risultato la cancellazione di una specifica riga della tabella, quella dove l'indice è a 12. > UPDATE provando SET nome2 = REPLACE(nome2, ' ', 'Mario') WHERE nome2 LIKE '% %' COLLATE utf8mb4_bin AND indice = 1 restituisce all riga dell'indice 1 Mario con la m maiuscola. 19.4.2016 > ORDER è la direttiva che ci permette di fare ordinamenti in modo ascendente ASC o discendente DESC. 1) SELECT country_id, name, code from country ORDER BY name DESC 2) SELECT nome, cognome, data_nascita FROM utenti ORDER BY data_nascita, nome prende in considerazione la data di nascita innanzitutto e poi, eventualmente, il nome. Per esempio alla seconda espressione possiamo aggiungere:
3) SELECT nome, cognome, data_nascita FROM utenti
ORDER BY data_nascita DESC, nome ASC Anche: 4) SELECT nome, cognome, data_nascita, DATE_FORMAT(data_nascita, "%d/%m/%Y") AS data_it FROM utenti ORDER BY data_nascita ASC 5) SELECT * FROM country ORDER BY code LIMIT 10,10 il LIMIT impagina i risultati (come per le pagine di GOOGLE). In questo caso 10 (il primo numero) stà per 1 primi dieci risultati, il secondo 10 stà per "mostra 10 risultati". Se scrivo 30,10 mi restituirà 10 risultati dal trentesimo in poi. 6) SELECT * FROM country WHERE name LIKE "a%" ---> mi restituisce una stringa che inizia per a ORDER BY code LIMIT 0,100 ----> mi restituisce i primi 100 records 7) SELECT * FROM stat WHERE reference <> "user_agent" AND reference LIKE "user_%" questo mi controlla se ci sia qualche stringa simile, ma non uguale a user_agent. > Per condividere il file country.sql abbiamo usato il prompt di DOS, prima per il database enaip e poi per quello enaip2: mysql -u root enaip < "i:\Grafico_pipol_2\SQL\country.sql" mysql -u root enaip2 < "i:\Grafico_pipol_2\SQL\country.sql" N.B.: per avere dei file.sql devo eseguire il DUMP. > La funzione COUNT. Restituisce il conteggio di un numero di valori non-NULL nelle righe richiamate da un'affermazione SELECT. SELECT COUNT(*) AS totale FROM stat WHERE reference LIKE "user_%" Funzione ROUND. Si usa per l'arrotondamento. Funzione RAND, cioè random, si usa per ordinare in modo casuale un database o generare numeri casuali. SELECT * FROM country ORDER BY RAND() mi restituirà i nomi dei paesi in modo casuale. > JOIN, mette insieme records di tabelle diverse. Abbiamo inoltre OUTER JOIN (LEFT JOIN) e INNER JOIN. SELECT * FROM country LEFT JOIN clienti ON(clienti.ks_paese = country.country_id) mi restituisce tutti i campi country e clienti, con questi ultimi a NULL. > Riepilogo: AS è una parola chiave. Fornisce un alias a colonne preesistenti. Consideriamo questo comando: SELECT first_name AS given_name, last_name AS surname FROM employees; mi restituisce gli stessi dati contenuti nelle colonne first_name e last_name sull'alias given_name e surname della tabella employees > LIKE, restituisce un risultato vero o falso in relazione all'accoppiamento fra caratteri.SELECT 'ä' LIKE 'ae' COLLATE latin1_german2_ci;> LEFT JOIN, stabilisce dove richiamare (su quello di sinistra) il database che deve essere unito all'altro. Con RIGHT JOIN lo stesso risultato sarà ottenuto, ma in direzione opposta. > LIMIT, impagina i risultati. 21.4.2016 > show processlist; (comando sql da DOS) > Per imparare ad usare l'SQL online: demo.myphpadmin.net/.... > Funzioni INNER JOIN, subSELECT, GROUP BY UTENTI CAP --------------------------------- -------------------------------------- | utenti_id | nome |cognome | cap | | cap | comune | targa | prov | | --------|--------|-------|------| |--------------------------------------| | | | | | | | | | | | | | | | | | | | | |--------------------------------- ---------------------------------------| La query INNER JOIN vale solo per i campi equivalenti. Restituisce 1 record solo. LEFT JOIN prende i dati della tabella di sinistra e cerca un riferimento nella seconda tabella, quella di destra. Il LEFT JOIN funziona con chiavi primarie+valori univoci. Il RIGHT JOIN è esattamente l'opposto del LEFT JOIN. Il NATURAL JOIN è sostituibile alla INNER JOIN. Esempio: LEFT JOIN cap ON(utente.paese_id = country.country_id) la riga risultante sarà aggiunta alla tabella di sinistra, laddove c'è il matching GROUP BY: questa clausola è soddisfatta attraverso la scannerizzazione dell'intera tabella e la creazione di una tabella temporanea dove tutte le righe da ogni gruppo sono consecutive. Poi, si usa la tabella temporanea per trovare i gruppi e applicarvi le funzioni aggregate. > importazione : mysql -u root nomedatabase <"percorso..." quando devo sospendere un'operazione, fino allo sblocco (unlock): lock tables 'country' write; unlock tables; > SELECT utenti.nome, utenti.cognome, country.name, country.code FROM utenti INNER JOIN9 country ON(utenti.country_id = country.country_id) AND country.active = "Y" > Le SUBSELECT SELECT utenti.nome (SELECT name FROM country WHERE country.country_id = utenti.country_id LIMIT 0,1) AS nome > Per avere l'ultimo login di un cliente, faccio una SELECT e poi una ODER BY: SELECT utenti.nome, utenti.cognome, (SELECT insert_date FROM stat WHERE stat.user_id = utenti.utente_id AND stat.reference = "login" ORDER BY insert_date DESC LIMIT 0,1) AS last_login (SELECT insert_date FROM stat WHERE stat.user_id = utenti.utente_id AND stat.reference = "logout" ORDER BY insert_date DESC LIMIT 0,1) AS last_logout DATEDIFF(last_logout, last_login) AS durata FROM utenti > Esercizio: dalla mia tabella clienti estrai il numero di clienti che hanno come nazionalità l'Italia e di sesso femminile: SELECT count(*) FROM clienti WHERE ks_paese LIKE 'Italia' AND sesso = 'f' > Esercizio: dalla mia tabella clienti estrai 1)il numero totale di pernottamenti e 2)il numero totale di notti pernottate: SELECT SUM(n_notti) FROM clienti; e poi SELECT SUM(n_pax) FROM clienti; Perciò con l'istruzione SUM faccio la somma del contenuto di tutti i campi n_notti e/o n_pax > Esercizio: aggiungere un campo C alla tabella clienti: ALTER TABLE clienti ADD C INT(100) NOT NULL; > Il comando mysqldump funziona da C: o da D:, non da mysql. Ad esempio, per il mio PC: D:\Programmi\EasyPHP-DevServer-14.1VC9\binaries\mysql\bin> mysqldump -u root prova > "D:\programmi\EasyPHP-DevServer-14.1VC9\binaries\mysql\bin\provaBackup.sql" If you get an error like: 'GTID_MODE' (1193) you can edit it as follows: mysqldump -u root –set-gtid-purged=OFF databasename > backup.sql With the command more backup.sql you can see what's in your backup. > Esercizio: SELECT COUNT(*) FROM clienti WHERE ks_paese = 'Svezia'; mi restituisce il numero di clienti con nazionalità o paese provenienza Svezia. > Esercizi: SELECT nome, cognome, ks_paese FROM clienti WHERE n_notti BETWEEN 3 AND 4; restituisce i campi nome, cognome e paese per pernottamenti fra le 3 e le 4 notti SELECT * FROM clienti WHERE ks_paese IN ('Italia', 'Francia', 'USA'); restituisce tutti i campi dove i paesi di provenienza sono Italia, Francia e USA SELECT ks_paese FROM clienti GROUP BY ks_paese; restituisce tutti i nomi dei paesi memorizzati SELECT COUNT(ks_paese) FROM clienti AS A WHERE ks_paese LIKE 'Germania'; restituisce il numero di records identificato con Germania SELECT DISTINCT ha lo scopo di eliminare i doppioni e creare una lista di valori univoci: SELECT DISTINCT ks_paese FROM clienti ORDER BY ks_paese ASC; 28.4.2016 GROUP BY. > SELECT lang_id, COUNT(lang_id) AS tot FROM stat GROUP BY lang_id mi restituisce il totale di records per ogni tipo di lingua. Similmente, sul mio DB clienti, per avere il totale di records per ogni paese, scriverò: SELECTks_paese, COUNT(ks_paese) AS tot FROM clienti GROUP BY ks_paese> SELECT lang_id, reference, COUNT(reference) AS tot FROM stat GROUP BY reference, lang_id mi restituisce il totale di records per lingua e categoria. Sul mio DB clienti, la query SELECTks_paese, email, COUNT(ks_paese) AS tot FROM clienti GROUP BY ks_paese, emailmi restituirà una lista di paesi ed emails con il totale ad 1, eccetto il caso in cui ci siano emails usate da più clienti (clienti diversi con stessa email). In questo caso mi restituisce la somma di volte in cui è stata trovata l'email. La query seguente che sarebbe uguale a quella precedente senza il campo email finale:SELECT ks_paese, email, COUNT(ks_paese) AS tot FROM clientiGROUP BY ks_paesemi restituisce una lista di paesi e prime email (la prima email trovata) e il totale di ricorrenze per paese. > SELECT lang_id, reference, COUNT(reference) AS tot FROM stat WHERE (reference = "login" OR reference = "logout") AND (YEAR(insert_date) = 2014 AND MONTH(insert_date) = 2)* GROUP BY reference, lang_id ORDER BY tot DESC * questa riga può anche essere sostituita da: (insert_date >= "2014-02-01 00:00:00 AND insert_date < "2014-03-01 00:00:00") Applicando la query al mio DB clienti:
SELECT
ks_paese, n_notti, COUNT(ks_paese) AS tot FROM clienti WHERE (sesso =
"f" OR sesso = "m") AND (n_notti > 1) GROUP BY
n_notti, ks_paese ORDER BY tot DESC
mi
restituisce una lista di paesi, per un numero di notti maggiore di 1
ed entrambi i sessi. Se, sempre dal mio DB clienti modifico
leggermente la mia query in:
SELECT
ks_paese, n_notti, COUNT(ks_paese) AS tot FROM clienti WHERE (sesso =
"f") AND(n_notti > 2) GROUP BY n_notti, ks_paese ORDER
BY tot DESC
mi
restituisce una lista di paesi con numero notti di pernottamento
superiore a due e totale dei records trovati.
>
SELECT lang_id, reference, reference_id,
COUNT(reference_id)
AS tot
FROM
stat WHERE reference = "news" AND(insert_date >=
"2014-01-01 00:00:00" AND insert_date <= "2014-12-31
23:59:59")
GROUP
BY reference_id, lang_id
HAVING
tot > 500
ORDER
BY tot DESC
>
Estrarre news non scadute: SELECT * FROM news WHERE expiry_date
>=
NOW()
per
le news passate, invece: SELECT * FROM news WHERE expiry_date <
NOW()
>
SELECT title, insert_date, category.name FROM news
LEFT
JOIN category ON(news.cat_id = category.cat_id)
WHERE
news.expiry_date >= NOW()
AND
news.active = 'Y'
>
SELECT ks_paese, sesso FROM clienti LEFT JOIN country
ON(country.country_id = clienti.ks_paese) WHERE clienti.n_notti >=
1 AND clienti.sesso = 'm'
mi
restituisce come risultato una lista di paesi e sesso clienti per un
numero di pernottamenti maggiore o uguale a 1 che abbia un match con
la tabella Country.
—
>
Le dichiarazioni (statement) GRANT, UPDATE, DELETE.
Con
GRANT ALL ON si danno tutti i permessi agli utenti per lavorare sui
DB.
GRANT
ALL ON enaip2.* <---- su tutte le tabelle del DB
GRANT
ALL ON enaip2.stat <---- solo sulla tabella stat
GRANT
ALL ON enaip2.* TO pippo@'localhost'
GRANT
ALL ON enaip2.* TO pippo@'172.16.%'
GRANT
ALL ON enaip2.* TO '%' (ci si può connettere da qualsiasi
postazione,
anche remota)
Possiamo
anche definire la password per l'utente: IDENTIFIED BY 'pluto'
>
Le repliche (REPLICATION)
Ci
consentono di creare dei cluster10
di SQL.
+---------------------+
+----------------------+
|
Server 1 | | Server 2
|
|
SQL |----------------------| SQL
|
|
| |
|
+---------------------+
+-----------------------+
Si
possono effettuare: repliche master-slave e master-master. Il master
contiene i dati reali, lo slave le repliche.
Tra
master e master la complicazione stà nell'auto-increment. In questo
caso un server fa l'auto-increment di record dispari e l'altro di
record pari e poi si scambiano i records.
Cosa
sono i PROXY? Sono dei piccoli server che mantengono in memoria solo
gli stati. Si interpongono tra un client ed un server facendo da
tramite o interfaccia tra i due host, inoltrando le richieste e le
risposte dall'uno all'altro. Il PROXY di solito lavora a livello
applicativo, gestendo un numero limitato di protocolli applicativi.
CLOUDFLARE.COM è un servizio PROXY gratuito in caso si abbia un sito
molto trafficato.
Per
quanto concerne le reti, il SOCKET è, nei sistemi operativi moderni,
un'astrazione software progettata per poter utilizzare delle API11
standard e condivise per la trasmissione e la ricezione di dati
attraverso una rete oppure come meccanismo di IPC12.
È il punto in cui un codice applicativo di un processo accede al
canale di comunicazione per mezzo di una porta, ottenendo una
comunicazione tra processi che lavorano su 2 macchine fisicamente
separate.
A
proposito di statistiche si può usare il formato JSON (JavaScript
Object Notation) per lo scambio dati in applicazioni client-server. È
usato in AJAX13
come alternativa a XML/XSLT ed è implementato e compilato nel PHP.
>
Per copiare (cioè, in definitiva, inserire) i dati in una tabella
vuota:
INSERT
INTO stat_old
SELECT
* FROM stat
WHERE
YEAR(insert_date) = 2014
Per
cancellare i dati:
DELETE
FROM stat WHERE YEAR(insert_date) = 2014
Con
OPTIMIZE, si riorganizza la memoria fisica dei dati e degli indici
delle tabelle per ridurre lo spazio utilizzato e migliorare
l'efficienza di input/output nell'accesso ai dati delle tabelle
stesse:
OPTIMIZE
TABLE stat
>
Con UNION si concatenano due risultati. UNION è l'unione di due
SELECT. Si usa per combinare il risultato di dichiarazioni SELECT
multiple in un singolo insieme di risultati.
>
Esempio: se vogliamo copiare i dati dalla tabella stat che abbiano
reference = login o logout e che siano degli anni dal 2012 al 2014,
scriveremo:
SELECT
* FROM stat
WHERE
(
reference = "login" or reference = "logout" )
AND
insert_date
>= "2012-01-01 00:00:00"
AND
insert_date
< "2015-01-01 00:00:00"
>
INSERT IGNORE INTO......
Aggiungendo
IGNORE dopo il comando INSERT, si invita il DBMS a non mostrare
errori nel caso si cerchi di inserire un valore duplicato per un
campo PRIMARY KEY o UNIQUE. Qualora questo succeda, MYSQL ignorerà
il comando.
Scarica il PDF: SQL e DB relazionali
1Simple Mail Transfer Protocol. È il protocollo standard per la trasmissione di e-mail via Internet. I protocolli utilizzati per ricevere posta sono invece il protocollo POP e l’IMAP.
2È un nodo ospite. Indica ogni terminale collegato attraverso link di comunicazione ad una rete informatica, come ad esempio Internet.
3È quell’operazione che permette il trasferimento dei dati da un computer ad un altro tramite una specifica porta di comunicazione. Questa tecnica può essere usata per permettere ad un utente esterno di raggiungere un host con indirizzo IP privato (all’interno di una LAN) mediante una porta dell’IP pubblico dello stesso. Per compiere questa operazione si ha bisogno di un router in grado di eseguire una traduzione automatica degli indirizzi di rete, detta NAT. Questo permette a computer esterni di connettersi a uno specifico computer della rete locale, a seconda della porta usata per la connessione.
4La scheda di rete è a livello logico un’interfaccia digitale, costituita a livello hardware da una scheda elettronica inserita/alloggiata solitamente all’interno di un personal computer, server, stampante, router ecc., che svolge tutte le elaborazioni o funzioni necessarie a consentire la connessione dell’apparato informatico ad una rete informatica.
5Il sistema dei nomi di dominio ( Domain Name System, DNS ), è un sistema utilizzato per la risoluzione di nomi dei nodi della rete (in inglese: host) in indirizzi IP e viceversa. Il servizio è realizzato tramite un database distribuito, costituito dai server DNS. Il DNS ha una struttura gerarchica ad albero rovesciato ed è diviso in domini (com, org, it, ecc.). Ad ogni dominio o nodo corrisponde un nameserver, che conserva un database con le informazioni di alcuni domini di cui è responsabile e si rivolge ai nodi successivi quando deve trovare informazioni che appartengono ad altri domini.
6 Nell’ambito dei database, ACID deriva dall’acronimo inglese Atomicity, Consistency, Isolation, e Durability (Atomicità, Coerenza, Isolamento e Durabilità) ed indica le proprietà logiche che devono avere le transazioni. Perché le transazioni operino in modo corretto sui dati è necessario che i meccanismi che le implementano soddisfino queste quattro proprietà: atomicità: la transazione è indivisibile nella sua esecuzione e la sua esecuzione deve essere o totale o nulla, non sono ammesse esecuzioni parziali; coerenza: quando inizia una transazione il database si trova in uno stato coerente e quando la transazione termina il database deve essere in un altro stato coerente, ovvero non deve violare eventuali vincoli di identità, quindi non devono verificarsi contraddizioni (inconsistenza) tra i dati archiviati nel DB; isolamento: ogni transazione deve essere eseguita in modo isolato e indipendente dalle altre transazioni, l’eventuale fallimento di una transazione non deve interferire con le altre transazioni in esecuzione; durabilità: detta anche persistenza, si riferisce al fatto che una volta che una transazione abbia richiesto un commit work, i cambiamenti apportati non dovranno essere più persi. Per evitare che nel lasso di tempo fra il momento in cui la base di dati si impegna a scrivere le modifiche e quello in cui li scrive effettivamente si verifichino perdite di dati dovuti a malfunzionamenti, vengono tenuti dei registri di log dove sono annotate tutte le operazioni sul DB.
7Il dump è un elemento di un database contenente un riepilogo della struttura delle tabelle del database medesimo e/o i relativi dati, ed è normalmente nella forma di una lista di dichiarazioni SQL. Tale dump è usato per lo più per fare il backup del database, poiché i suoi contenuti possono essere ripristinati nel caso di perdita di dati.
8Le viste sono un modo di mostrare i dati di un DB con una struttura diversa da quela effettiva del DB. Un uso delle viste è quello di concedere l’accesso ad un utente ad una tabella mostrandogli solo alcune colonne . Inoltre, si possono leggere dati da altre tabelle attraverso JOIN o UNION.
9Si può usare qui anche una LEFT JOIN .
10Un cluster è un insieme di computer connessi tramite una rete telematica, ma può anche essere un raggruppamento logico di settori contigui in un disco rigido.
11Con Application Programming Interface si indica un insieme di procedure disponibili al programmatore. Con questo termine spesso si intendono le librerie software disponibili in un certo linguaggio di programmazione.
12Con Inter-Process Communication ci si riferisce a tutte quelle tecnologie software il cui scopo è consentire a diversi processi di comunicare tra loro scambiandosi dati ed informazioni.
13Acronimo di Asynchronous JavaScript and XML. È una tecnica di sviluppo software per la realizzazione di applicazioni web interattive. Lo sviluppo di applicazioni HTML con AJAX si basa su uno scambio di dati in background fra web browser e server che consente l’aggiornamento dinamico di una pagina web senza esplicito ricaricamento da parte dell’utente.
Be the first to comment on "SQL e DB relazionali."